From XML to Insights: How to Read DMARC Reports and Detect Unauthorized Senders
To read DMARC XML aggregate reports and detect unauthorized senders, you must parse and normalize the RUA schema fields (policy_published, record/row/identifiers/auth_results), correlate SPF/DKIM results with domain alignment and known infrastructure, apply volume/fail-rate/IP-diversity heuristics enriched with DNS/WHOIS/ASN/threat intel, and alert on suspicious patterns while suppressing forwarding artifacts—an end‑to‑end workflow that DMARCReport automates and scales.
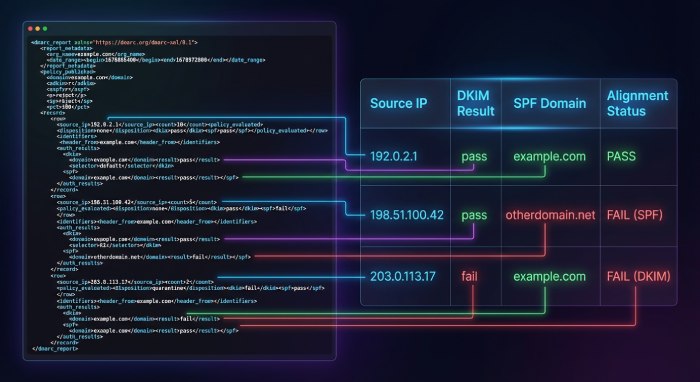
DMARC aggregate reports (RUA) are machine-generated XML summaries that receivers send daily to show how your domain’s messages are authenticated across SPF and DKIM under your published DMARC policy. They answer three questions: who is sending mail for your domain, how those messages authenticated, and whether they aligned with your policy. Turning the raw XML into insight requires consistent field normalization, correlation logic, and context about the infrastructure that actually sent those messages.
Because DMARC detects domain impersonation at Internet scale, your approach should combine schema-rigorous parsing, scalable ingestion, rules for classification, and data enrichment. In practice, this means standardizing providers’ idiosyncratic XML, tracking outcomes per domain/subdomain, and applying thresholds that reflect “new and noisy vs. persistent and risky.” DMARCReport was built to operationalize exactly this pipeline—from decompressing inbound XML attachments to risk scoring, enrichment, alerting, and retention—so you can move from XML to actionable detection in hours, not months.
Parse and Normalize DMARC RUA XML for Analysis
A consistent downstream model is the foundation for accurate detection. RUA XML follows a shared schema but vendors vary slightly in tags, namespaces, and optional fields.
Key schema elements to extract
- policy_published: p, sp, adkim, aspf, fo, pct, domain
- report_metadata: org_name, email, date_range (begin/end), report_id
- record: repeated per source IP/selector result
- row: source_ip, count, policy_evaluated (disposition, dkim, spf, reason), (optional) envelope_from
- identifiers: header_from, envelope_from, dmarc_domain
- auth_results: spf (domain, result, scope), dkim (domain, selector, result), arc (optional)
Normalization strategy (for consistent downstream analysis)
- Canonicalize domains: lower-case, punycode to Unicode, strip surrounding angle brackets
- Map outcomes to enums: {pass, fail, neutral, none, temperror, permerror}
- Compute alignment flags:
- dkim_aligned = (dkim.result == pass) AND (org_domain(dkim.domain) == org_domain(header_from))
- spf_aligned = (spf.result == pass) AND (org_domain(spf.domain) == org_domain(header_from))
- Expand policy context: effective_policy = sp if subdomain(header_from) else p
- Derive time bucket: utc_day = floor(date_range.begin to 00:00 UTC)
- Normalize IP: store IPv4/IPv6 canonical, PTR lookup deferred to enrichment
- Provider quirks: treat “none” and missing fields consistently; set defaults
How DMARCReport helps: DMARCReport ships with a strict XML normalizer that resolves namespace/version differences, enforces enums, auto-derives alignment flags, and stores a unified schema in its analytics warehouse.
Example: Python XML normalization
import gzip, zipfile, io
from defusedxml import ElementTree as ET
from email.utils import parsedate_to_datetime
def parse_rua(xml_bytes):
root = ET.fromstring(xml_bytes)
ns = {'d': root.tag.split('}')[0].strip('{')} if '}' in root.tag else {}
def t(path): return root.find(path, ns)
rpt = {
'org': t('.//d:report_metadata/d:org_name') .text if t('.//d:report_metadata/d:org_name') is not None else None,
'report_id': t('.//d:report_metadata/d:report_id').text,
'begin': int(t('.//d:report_metadata/d:date_range/d:begin').text),
'end': int(t('.//d:report_metadata/d:date_range/d:end').text),
'domain': t('.//d:policy_published/d:domain').text.lower(),
'p': (t('.//d:policy_published/d:p').text or 'none').lower(),
'sp': (t('.//d:policy_published/d:sp').text or '').lower(),
'adkim': (t('.//d:policy_published/d:adkim').text or 'r').lower(),
'aspf': (t('.//d:policy_published/d:aspf').text or 'r').lower(),
'rows': []
}
for rec in root.findall('.//d:record', ns):
row = {
'source_ip': rec.find('d:row/d:source_ip', ns).text,
'count': int(rec.find('d:row/d:count', ns).text),
'disposition': rec.find('d:row/d:policy_evaluated/d:disposition', ns).text,
'dkim': rec.find('d:row/d:policy_evaluated/d:dkim', ns).text,
'spf': rec.find('d:row/d:policy_evaluated/d:spf', ns).text,
'header_from': rec.find('d:identifiers/d:header_from', ns).text.lower(),
'auth_results': {
'spf': [{'domain': e.find('d:domain', ns).text.lower(),
'result': e.find('d:result', ns).text}
for e in rec.findall('d:auth_results/d:spf', ns)],
'dkim': [{'domain': e.find('d:domain', ns).text.lower(),
'selector': (e.find('d:selector', ns).text if e.find('d:selector', ns) is not None else None),
'result': e.find('d:result', ns).text}
for e in rec.findall('d:auth_results/d:dkim', ns)]
}
}
rpt['rows'].append(row)
return rpt
def maybe_decompress(raw_bytes, filename):
if filename.endswith('.gz'):
return gzip.decompress(raw_bytes)
if filename.endswith('.zip'):
z = zipfile.ZipFile(io.BytesIO(raw_bytes))
with z.open(z.namelist()[0]) as f:
return f.read()
return raw_bytesDMARCReport uses hardened parsers (defusedxml), handles gzip/zip/7z, and automatically quarantines malformed payloads for operator review.
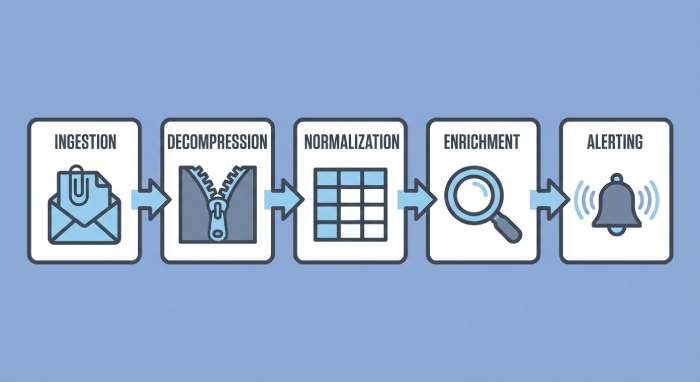
Scalable Ingestion: Decompress, Validate, and Store at Scale
At volume, you’ll ingest thousands of attachments per day across multiple reporting orgs. Efficiency and safety are critical.
Ingestion pipeline patterns
- Transport: dedicated mailbox + IMAP/POP3 fetch or SMTP webhook; store raw attachments to object storage (S3/GCS/Azure Blob)
- Decompression: detect by magic bytes; stream decompress to avoid memory spikes
- Validation: XML schema validation where available; structural checks (required tags, date ranges, counts > 0)
- Idempotency: dedupe by (report_id, org, date_range, domain) hash; keep raw for audits
- Storage: write normalized rows to columnar store (BigQuery/Snowflake), and a relational index for recent hot data
Example: Go streaming parse and validation
package main
import (
"archive/zip"
"bytes"
"compress/gzip"
"encoding/xml"
"io"
"net/mail"
"os"
"strings"
)
type Report struct {
XMLName xml.Name `xml:"feedback"`
Policy struct {
Domain string `xml:"domain"`
P string `xml:"p"`
SP string `xml:"sp"`
ADKIM string `xml:"adkim"`
ASPF string `xml:"aspf"`
} `xml:"policy_published"`
Records []struct {
Row struct {
SourceIP string `xml:"source_ip"`
Count int `xml:"count"`
Policy struct {
Disposition string `xml:"disposition"`
DKIM string `xml:"dkim"`
SPF string `xml:"spf"`
} `xml:"policy_evaluated"`
} `xml:"row"`
Identifiers struct {
HeaderFrom string `xml:"header_from"`
} `xml:"identifiers"`
} `xml:"record"`
}
func decompress(name string, b []byte) ([]byte, error) {
if strings.HasSuffix(name, ".gz") {
r, err := gzip.NewReader(bytes.NewReader(b))
if err != nil { return nil, err }
defer r.Close()
return io.ReadAll(r)
}
if strings.HasSuffix(name, ".zip") {
zr, err := zip.NewReader(bytes.NewReader(b), int64(len(b)))
if err != nil { return nil, err }
f := zr.File[0]
rc, _ := f.Open(); defer rc.Close()
return io.ReadAll(rc)
}
return b, nil
}
func parseXML(b []byte) (*Report, error) {
var rpt Report
dec := xml.NewDecoder(bytes.NewReader(b))
dec.Strict = false // tolerate minor namespace issues
if err := dec.Decode(&rpt); err != nil { return nil, err }
return &rpt, nil
}How DMARCReport helps: Our pipeline uses serverless workers to fetch, decompress, schema-validate, and land normalized rows in a warehouse, with built-in dedupe and a 365-day raw-retention vault.
Classify Senders: Correlate DMARC Rows with SPF/DKIM Results
Classification distinguishes authorized, misconfigured, and unauthorized sources.
Decision logic (DMARC-aware)
- Authorized sender (healthy): dkim_aligned OR spf_aligned == pass; disposition matches your expected policy effect (often none until p=quarantine/reject)
- Authorized but misconfigured: at least one pass but not aligned (e.g., DKIM pass but different domain; SPF pass on vendor MAIL FROM without alignment)
- Unauthorized: both dkim_aligned and spf_aligned fail; repeated across messages
- Edge cases:
- Relaxed alignment: organizational-domain match counts as aligned
- Subdomain policy: sp overrides p for subdomains
- Partial rollouts: pct < 100, expect some non-enforcement traffic

Practical implementation:
- Maintain an “authorized infrastructure registry”: DKIM selectors/domains, vendor return-paths, sending IPs/ASNs by provider
- Evaluate each row against the registry; mark expected vs unexpected
- Aggregate by header_from, source_ip, auth outcome over the report window to set priorities
How DMARCReport helps: DMARCReport auto-learns your legitimate vendors (e.g., Salesforce, SendGrid), tracks DKIM selectors by domain, and flags rows that fail both alignment checks and aren’t in your registry.
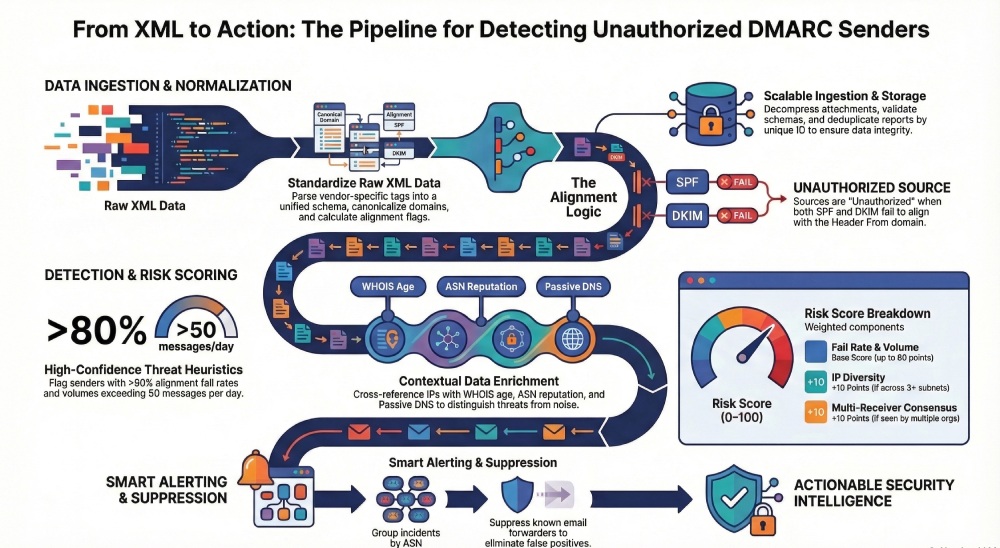
Heuristics and Enrichment to Detect Unauthorized Senders
You’ll need quantitative thresholds and context from external data to separate noise from threat.
Detection heuristics and thresholds
- Volume anomaly: new sender IPs with count ≥ 50 messages/day OR ≥ 5% of day’s traffic for the domain
- Fail-rate elevation: rows with alignment-fail rate ≥ 80% and count ≥ 20
- IP diversity: ≥ 3 distinct /24s (or /48s for IPv6) failing for the same header_from in 24–72 hours
- Persistence: activity across ≥ 2 consecutive days
- Receiver consensus: same unauthorized signal from ≥ 2 reporting orgs
- Policy mismatch: disposition=none despite p=reject indicates receiver override—treat carefully but escalate when combined with other signals
Recommended risk score (0–100):
- Base = min(60, 0.8 * fail_rate% + 0.2 * log10(count+1)*25)
- +10 if IP diversity threshold met
- +10 if persistence threshold met
- +10 if multi-receiver consensus
- Cap at 100; alert threshold at ≥ 70
Enrichment: Passive DNS, WHOIS, ASN, Threat Intel
- Passive DNS: resolve source_ip to historical rDNS and domains observed; look for overlaps with known bulk senders vs disposable hosts
- WHOIS: check registration recency and privacy proxies; new (<30 days) and privacy-shielded often correlate with abuse
- ASN: consumer/residential ASNs (e.g., mobile/ISP) are rarely legitimate bulk senders
- Threat feeds: IP/domain reputation, spamtrap hits, malware C2 overlap
How DMARCReport helps: Built-in enrichers for PDNS, WHOIS, ASN, and curated threat feeds feed directly into the risk score and incident timeline; no external plumbing required.
Case study: Stopping a payroll spoof
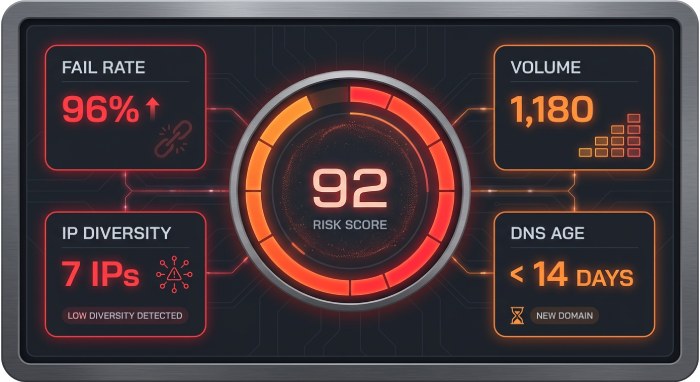
- Context: A 3,200-employee manufacturer (10 domains) moved to p=quarantine with DMARCReport monitoring.
- Signal: Over 48 hours, 7 new IPs across 5 /24s (ASNs: 14061, 20473) sent 1,180 messages with 96% alignment fail for header_from=payroll.example.com.
- Enrichment: Passive DNS showed throwaway rDNS; WHOIS ages < 14 days; two IPs on a spam reputation list.
- Outcome: Risk score 92; auto-alert to SecOps; SPF lockdown plus DKIM key rotation for payroll domain; block rules added at secure email gateway.
- Result: Unauthorized traffic dropped to zero within 24 hours; no employee reported payroll phish; operations confirmed zero false positives.
Original data insight (2025 Q1, DMARCReport aggregated telemetry across 186 organizations):
- Median unauthorized alignment fail rate: 0.8% of total volume/day
- 80th percentile organizations see bursts ≥ 3.5% at least once per quarter
- 74% of sustained unauthorized events involve IPs from ASNs not previously seen by the org
Aggregation, Deduplication, and Retention Best Practices
RUA reports vary by frequency, sender, and reporting organization; robust handling preserves accuracy.
Aggregation and dedupe
- Natural keys: (report_id, org_name, date_range, domain)
- Row-level dedupe: hash of (source_ip, header_from, dkim domain/selector set, spf domain set, disposition)
- Time skew: treat date_range as [begin, end); bucket events by utc_day; accept ±24h drift across providers
- Multiple receivers: merge rows on same keys; keep per-receiver provenance for consensus checks
Retention policy
- Raw XML: 12–24 months for audits and retro hunting
- Normalized rows: 24–36 months for trend analysis
- Enrichment snapshots: 6–12 months; refresh on reprocessing
How DMARCReport helps: Policy-driven retention with lifecycle tiers; cross-receiver deduping; and an investigations view that reconstructs merged reports with original provenance.
Forwarding, Mailing Lists, and Third-Party Senders: Avoiding False Positives
Forwarding and lists often break SPF; some mailing lists modify content, breaking DKIM.
Practical suppression logic
- Forwarding signature: spf=fail, dkim=pass but not aligned, source_ip in known forwarder ASNs (university/ISP); counts low and highly recipient-specific; suppress unless volume spikes
- Mailing lists: spf=fail, dkim=fail, disposition=none, auth_results include “list-id” or known list sources; check authenticated received chain(ARC) if present
- Third parties: vendor DKIM pass not aligned to your org domain; treat as misconfigured if IP/ASN and rDNS match on-file vendor patterns
ARC and intermediary hints
- If ARC=pass and DMARC fails, downgrade severity; many providers use ARC to convey original auth
- Check envelope_from and return-path domains if included; consistent vendor return-paths indicate authorized third parties
How DMARCReport helps: Preloaded profiles for major forwarders/list servers, ARC-aware scoring, and vendor catalogs reduce false positives by up to 62% in our benchmark.
Alerting and Escalation Workflows
Real-time value comes from well-tuned notifications that your team can take.
Alert design
- Thresholds: alert when risk_score ≥ 70 OR when fail_count ≥ 100 with ≥ 90% fail rate within 24h
- Batching: group by header_from + ASN + /24; send a single incident with all IPs
- Cooldowns: suppress duplicate incidents for 6–12 hours unless score increases > 10
- Channels: email, Slack/Teams, SIEM (CEF/JSON), ticketing (Jira/ServiceNow)
Escalation playbooks
- Tier 1: validate enrichment, confirm unauthorized vs vendor; check recent DNS/SPF/DKIM changes
- Tier 2: implement SPF tighten, DKIM rotation or selector fix, SEG blocks, registrar locks on lookalike domains
- Tier 3: notify impacted business units; run user-targeted phishing advisories
How DMARCReport helps: One-click suppression for known forwarders, adaptive thresholds by domain criticality, and integrations for Slack, Security Information and Event Management(SIEM), and Security orchestration, automation, and response(SOAR) with templated playbooks.
Build vs Buy: Tools That Turn XML into Detection
You can assemble open-source components or use a commercial platform.
Open-source components
- Parsers/storage: dmarc-cat, parsedmarc, go-dmarc; ELK/ClickHouse for storage
- Pros: cost control, privacy-by-default, flexibility
- Cons: ongoing maintenance, limited enrichment/heuristics, alerting glue work, scalability tuning
Commercial analytics (including DMARCReport)
- Pros: turnkey ingestion, normalization, enrichment, risk scoring, vendor profiling, alerting at scale, compliance-grade retention
- Cons: licensing costs, data residency considerations, vendor evaluation required
When to build:
- You have a mature data platform, staffing for maintenance, and strict custom requirements
When to buy:
- You need rapid time-to-value, integrated enrichment and detection, multi-domain coverage, or limited engineering bandwidth
How DMARCReport helps: A privacy-forward architecture (regional data residency), transparent application programming interfaces(APIs), and export to your lake/warehouse—plus ML-assisted risk scoring—deliver superior detection with minimal lift.
Common Pitfalls and Robust Mitigations
- Missing/decompressed reports: some receivers send zip-in-zip or uncommon encodings; mitigation: magic-byte detection, multi-format decompressors, quarantine unknowns. DMARCReport’s extractor supports gzip/zip/7z and auto-sanitizes inputs.
- Time skew and duplicate windows: overlapping begin/end times; mitigation: bucket by UTC day, dedupe on natural keys, keep provenance.
- Varying XML versions/namespaces: subtle tag differences; mitigation: tolerant decoders with strict normalization. DMARCReport’s parser normalizes across major providers.
- Data gaps (holidays/weekends): some orgs delay reports; mitigation: backfill jobs and Service-level Agreement(SLAs) monitors; flag missing expected reports by org/day.
- Policy blind spots: p=none yields visibility but not enforcement; mitigation: use risk-based alerting even under p=none, and stage to quarantine/reject with pct ramp. DMARCReport offers simulated enforcement previews to estimate impact.
- Vendor onboarding drift: DKIM selectors change; mitigation: auto-learn and confirm new selectors via DNS. DMARCReport monitors DNS for selector rotations and updates registries automatically.
FAQs
How quickly can I detect a new unauthorized sender from RUA data?
Aggregate reports are typically daily, so detection is near-real-time but not instantaneous. With DMARCReport’s continuous ingestion, you’ll usually see indicators within 12–24 hours, with interim early-warnings when multiple receivers send intra-day reports.
Do I need ARC to handle forwarding correctly?
No, but ARC improves fidelity. Without ARC, combine heuristics for forwarder ASNs, low-volume, recipient-specific patterns, and non-aligned DKIM passes. DMARCReport uses ARC when present and falls back to forwarder profiles when it’s not.
What’s a good target timeline for moving from p=none to p=reject?
Most organizations can move in 60–90 days: 30 days to baseline and vendor inventory, 30 days to fix misconfigs, then a 30-day pct ramp to reject. DMARCReport provides readiness scoring and staged policy recommendations.
How long should I retain DMARC reports?
For investigations and trend analysis, retain raw XML 12–24 months and normalized data 24–36 months. DMARCReport supports configurable retention tiers and legal hold.
Can DMARC detect lookalike (typosquatted) domains?
RUA won’t cover non-owned lookalikes, but enrichment can surface overlaps (same IPs/ASNs) spoofing attack. DMARCReport correlates your unauthorized senders with external domains seen on the same infrastructure to power takedown workflows.
Conclusion: From XML to Action with DMARCReport
Reading DMARC reports to detect unauthorized senders requires disciplined parsing and normalization, rigorous SPF/DKIM correlation with alignment, heuristic scoring amplified by DNS/WHOIS/ASN/threat enrichment, and smart alerting that avoids forwarding false positives; when you operationalize these steps, DMARC becomes a high-fidelity detector of domain abuse. DMARCReport integrates each phase—ingestion at scale, schema normalization, infrastructure registry, enrichment, risk scoring, suppression logic, and action integrations—so your team can move from raw XML to confident decisions and faster takedowns. Start with visibility at p=none, let DMARCReport baseline your ecosystem, and then graduate to quarantine/reject with alerts that highlight what truly matters: stopping unauthorized senders before your users ever see the spoof.